
Pytanie: Czy Twoja siłownia zatrudnia analityka danych?
No wiesz, kogoś, który analizuje tony danych o klientach siłowni na ciemnym zapleczu, rzadko wyskakując z biura, aby zrobić biceps w przerwach między wdrażaniem algorytmów klasyfikacji dla różnych modeli uczenia maszynowego?
Nie sądzę, by tak było.
Bądźmy szczerzy: w ciągu ostatnich kilku lat wiele siłowni odrzuciło drukowanie 20-stronicowych umów członkowskich, kserowanie praw jazdy i wypełnianie kopert kuponami. Placówki przeszły do modernizowania różnych operacji klubowych za pomocą kiosków samoobsługowych, kontroli dostępu i zautomatyzowanej korespondencji z klientami.
Widać, że przeszliśmy długą drogę. Co dalej?
Coraz więcej firm zwraca się ku analityce opartej na prawdopodobieństwie, aby pomóc sobie w podejmowaniu decyzji. Branża zarządzania siłowniami jest na granicy zrobienia tego samego.
Ale jeśli spojrzeć poza wielkie korporacje centrów fitness, praktycznie żaden klub nie zatrudnił wewnętrznego analityka do tworzenia prognoz lub zaleceń dotyczących różnych procesów klubowych w oparciu o dane klientów.
A biorąc pod uwagę, że analityka jest teraz bardzo ważna w prawie każdej branży, nadszedł czas, aby siłownie stały się "mądrzejsze", i w końcu wykorzystały duże ilości danych klientów, które mają do dyspozycji. W rezultacie będą mogły podejmować bardziej świadome decyzje.
To prowadzi nas do uczenia maszynowego, czyli procesu wdrażania złożonych algorytmów, które uczą się przewidywać lub wnioskować o wynikach na podstawie analizy danych.
Uczenie maszynowe jest już szeroko stosowane w różnych branżach, takich jak, między innymi:
- Sprzedaż detaliczna online
- Samochody samojezdne
- Giełda finansowa
- Wyszukiwarki internetowe
- Firmy rozrywkowe
Wielkim węzłem, który wiąże wszystkie te branże, są oczywiście dane... ogrom danych.
To właśnie dzięki gromadzeniu i analizie tych danych za pomocą uczenia maszynowego te branże - jak handel elektroniczny - zwiększają swoje przychody ze sprzedaży o 5-20%..
Należy jednak pamiętać, że w zarządzaniu siłownią sprzedaż to tylko połowa sukcesu - trzeba się też martwić o utrzymanie klientów! Ostatecznie, uczenie maszynowe może zapewnić klubom:
- Przewidywania przychodów
- Prognozy rezygnacji
- Rekomendacje dotyczące zajęć
- Rekomendacje produktów
- Systemy motywacji dla klientów.
Po przeanalizowaniu danych i opracowaniu prognoz, dzięki zastosowaniu sztucznej inteligencji, można automatycznie podjąć najbardziej odpowiednie działania.
Ale zanim przejdziemy do sedna sprawy, pokażemy Ci, jak uczenie maszynowe działa w połączeniu z zarządzaniem klubem.
Zbieranie danych
Tak jak samochód potrzebuje benzyny, algorytmy uczenia maszynowego potrzebują danych do analizy i przetwarzania w celu przewidywania wyników i formułowania zaleceń.
Na szczęście, branża fitness jest już przesycona zintegrowanymi aplikacjami i urządzeniami, które działają jako kolektory danych. Te informacje są w stanie zasilić proces uczenia maszynowego. Dane są dostępne w każdej chwili - od liczników kalorii po nadajniki (z ang. trackers) treningowe i FitBity.
Ale nawet bez aplikacji firm trzecich, Twój klub prawdopodobnie posiada już wystarczającą ilość danych o klientach, aby tworzyć inteligentne rekomendacje i prognozy na podstawie:
- Historii obecności
- Wieku
- Płci
- Historii zakupów klubowych
- Historii rezerwacji
To oczywiście tylko kilka zbiorów danych, które mogą pomóc w określeniu konkretnych wyników, takich jak wskaźnik rezygnacji lub rekomendacje dotyczące zajęć. Niemniej, możliwości są niemal nieograniczone, w zależności od tego, jakie rodzaje sygnałów (z ang. beacons) do zbierania danych zintegrowałeś ze swoim systemem.
Proces uczenia się
Po uzyskaniu tych danych (za zgodą klienta) można je wykorzystać jako zestaw treningowy do uczenia się algorytmów uczenia maszynowego.
Uczenie maszynowe to w zasadzie duży element sztucznej inteligencji (z ang. AI), który informuje o procesie podejmowania decyzji poprzez znajdowanie korelacji między różnymi zbiorami danych.
Korzystając z różnych algorytmów, moduł uczenia maszynowego uczy się w sposób nadzorowany na "zbiorze treningowym", gdzie każdemu wprowadzonemu zestawowi danych lub "wejściu" towarzyszy oczekiwany wynik lub "wyjście".
Jeśli chcielibyśmy sklasyfikować coś jako jabłko lub nie-jabłko, moglibyśmy użyć tych zbiorów danych - równomiernie ważonych - by otrzymać nasz wynik:
- Czerwone = T/N
- Okrągły = T/N
- Owoc = T/N
- Waga między 70-100 gramów T/N
W niektórych zestawach treningowych, chcąc podkreślić prawdopodobieństwo występowania danej cechy, nadajemy jej odpowiednią wagę. W naszym przykładzie z jabłkiem daliśmy każdej zmiennej wejściowej taką samą wagę.
Zatem jeśli obiekt ma ¾ z tych oczekiwanych danych wejściowych, to prawdopodobieństwo, że będzie to jabłko - w naszym modelu - wynosi 75%.
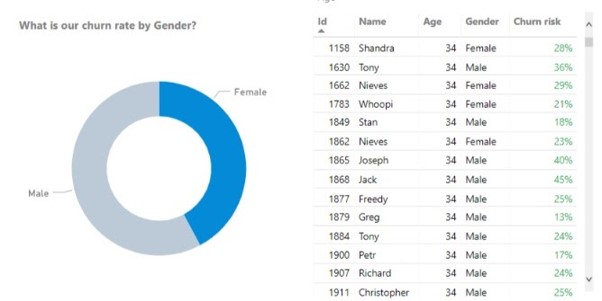
Wracając do zarządzania klubem, załóżmy, że chcemy przewidzieć, którzy klienci klubu będą w najbliższej przyszłości rezygnować, a którzy nie.
Gdybyśmy wzięli wszystkie wymienione powyżej zbiory danych dotyczące klientów siłowni w ostatnim roku, moglibyśmy oznaczyć wynik jako "rezygnacja" lub "brak rezygnacji" na podstawie tego, czy klient finalnie zrezygnował, czy nie.
Następnie trenujemy algorytm, zapisując w zbiorze treningowym wszystkie dane wejściowe dla każdego klienta (frekwencja, wiek, płeć itp.) wraz ze zdefiniowanymi etykietami ("zrezygnował" lub "nie zrezygnował").
Ponieważ chcemy wyrazić nasze wyniki jako prawdopodobieństwa, możemy przypisać każdej zmiennej wejściowej "wagę", przy czym niektórym z nich przypisujemy większą wagę niż innym.
Z czasem algorytm będzie przypisywał wagi różnym zmiennym, gdy będzie się uczył.
Nasz zbiór treningowy może wyglądać tak jak ten, ale z dużo większą liczbą danych wejściowych:

Po "nauczeniu się" danych usuwamy oczekiwane etykiety ("zrezygnował" lub "nie zrezygnował") i sprawdzamy, czy model potrafi poprawnie wykorzystać dane wejściowe, które otrzymał, do przewidywania wyników na podstawie danych, których się nauczył.
Po przepuszczeniu różnych modeli przez zbiory treningowe sprawdzamy ich dokładność w zbiorach testowych i wybieramy najdokładniejszy i najbardziej stabilny (różnica dokładności między zbiorami treningowym i testowymi) wariant.
Można to również wykorzystać do innych celów, takich jak rekomendacje produktów w zależności od produktu, typu rekomendacji i innych zmiennych.
Gdy mamy już sklasyfikowane grupy ("ryzyko rezygnacji" i "brak ryzyka rezygnacji"), czas na podjęcie działań.
Inteligencja
Sztuczna inteligencja pełni ostatecznie rolę worka, do którego można wrzucić różne systemy i procesy analityki predyktywnej, uczenia maszynowego, języka, wizji oraz innych systemów i procesów komunikacyjnych.
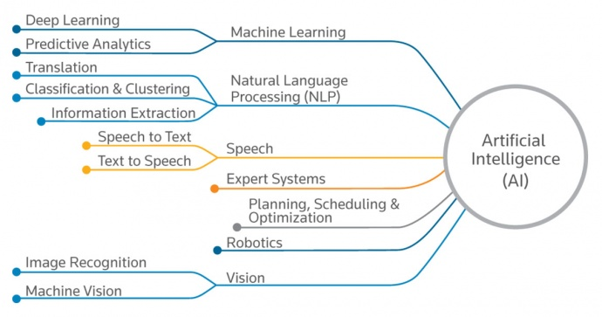
Gdy mamy już model uczenia maszynowego, który został zweryfikowany i wdrożony do produkcji, wykorzystujemy dane do stworzenia środowiska, z którego może czerpać nasza sztuczna inteligencja.
Kiedy dane zostaną zebrane przez uczenie maszynowe i będą gotowe do użycia, procesy automatyzacji sztucznej inteligencji rozpoczną się od testowania A/B różnych kanałów komunikacji i wiadomości, aby dowiedzieć się, które z nich są najbardziej skuteczne.
Na przykład, uczenie maszynowe może zalecić, aby określonej grupie klientów klubu zaoferować pakiet szkoleń osobistych lub obniżone ceny członkostwa.
Klub stworzyłby kilka różnych komunikatów dotyczących tej samej oferty, z których sztuczna inteligencja mogłaby wybierać. Następnie sztuczna inteligencja przetestowałaby każdą z nich, oceniła wyniki i wybrała najlepiej działające opcje dla podobnych odbiorców w przyszłości.
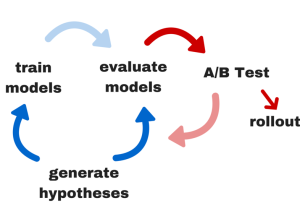
Oczywiście "na zapleczu" jest jeszcze wiele innych, zmiennych elementów, ale to tylko ogólny zarys tego, jak odbywa się selekcja treści.
Teraz, gdy znamy już ogólny proces, przyjrzyjmy się kilku konkretnym przypadkom zastosowań tego rozwiązania w klubach.
Inteligentna siłownia
Wykorzystując procesy uczenia maszynowego, kluby mogą teraz przewidywać i rekomendować szeroki wachlarz działań, aby nie tylko poprawić wyniki finansowe, ale także sprawić, by klienci byli zadowoleni i chętni do osiągnięcia swoich celów.
Pamiętaj, że ludzie przychodzą na siłownię mając na celu samodoskonalenie. Wszelkie ulepszenia w sposobie nawiązywania z nimi kontaktu mogą stanowić różnicę między niekompletnym postanowieniem noworocznym, a odmienionym życiem - na dłuższą metę i na lepsze.
Rekomendacje produktów
Stare porzekadło głosi, że "klient ma zawsze rację".
Motto to wywodzi się z podstawowego porozumienia między sprzedawcą a konsumentem: nie wiesz, czego chce klient, dopóki o to nie poprosi.
W dzisiejszych czasach klienci korzystający z usług fitness są często zbyt zajęci, aby podnieść słuchawkę telefonu i samodzielnie odnowić członkostwo lub by poczekać dodatkowe pięć minut w recepcji w celu odbioru napoju potreningowego.
Dlatego właśnie rekomendacje produktów są powszechne niemal w każdym internetowym handlu detalicznym. Powoli stają się one w coraz większym stopniu oparte na procesach uczenia maszynowego w celu zwiększenia sprzedaży.
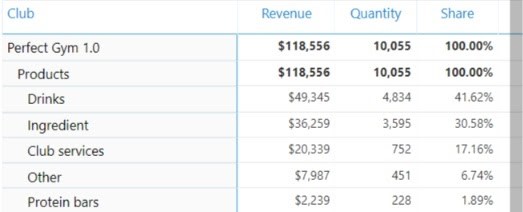
Rekomendacje te są określane przez różne algorytmy uczenia maszynowego. Mogą one być oparte na algorytmach uczenia nienadzorowanego, które znajdują korelacje między zakupionymi produktami.
Na przykład algorytmy te mogą wykryć, że osoby kupujące białko w proszku i kreatynę często kupują również napoje przedtreningowe. Algorytmy te znajdą te korelacje i będą rekomendować napoje przedtreningowe osobom, które często kupują dwa pozostałe produkty.
Rekomendacje mogą również opierać się na algorytmach uczenia nadzorowanego. Jednym z jego przykładów jest to, że wiele osób, które miały wspólną zmienną wyjściową (zakup batonu proteinowego), miało również wiele wspólnych zmiennych wejściowych (częste uczęszczanie na zajęcia, podobne członkostwo, płeć, wagę itp.). System uczy się i jest odpowiedzialny za rekomendację podobnych produktów dla przyszłych klientów, którzy mieliby podobne zmienne wejściowe.
Efektem końcowym jest imponujący system reguł asocjacyjnych, który jest wykorzystywany podczas rekomendowania produktów klientom - zarówno na recepcji, jak i w kontaktach online czy podczas działań promocyjnych.
Rekomendacje zajęć
Wykorzystując podobne techniki, jak w przypadku rekomendacji produktów, możemy przewidzieć, jakie zajęcia należy zaoferować, aby zwiększyć liczbę rezerwacji i podnieść frekwencję.
Zbieranie danych za pomocą sygnalizatorów (z ang. beacons) jest w tym przypadku nieco bardziej złożone, ponieważ wymaga bardziej szczegółowych danych o uczestnikach, takich jak:
- Częstotliwość uczęszczania na zajęcia
- Częstotliwość rezerwacji zajęć
- Oceny zajęć
- Cele klienta
- Preferencje treningowe uczestników
To tylko kilka punktów, które można wykorzystać jako zmienne wejściowe. Gdy przeanalizujesz je wraz z innymi danymi, system może skłonić Cię do zastąpienia pewnych zajęć innymi, aby zwiększyć zaangażowanie danych klientów.
Takie rezultaty można uzyskać za pomocą algorytmów uczenia nadzorowanego, nienadzorowanego lub obu. Efektem końcowym są rekomendowane zajęcia wraz z przewidywanym wzrostem frekwencji.
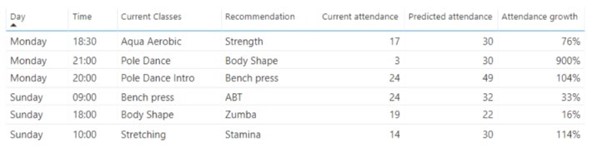
Wiele algorytmów rekomendacji wykorzystuje kombinację technik uczenia nadzorowanego i nienadzorowanego; najważniejszym aspektem jest jednak to, że algorytmy uczą się, które rekomendacje są skuteczne, i z czasem je ulepszają.
Przewidywania dotyczące frekwencji
Ilu klientów będzie w klubie w danym dniu? Ilu z nich będzie zupełnie nowymi użytkownikami? Jakie grupy wiekowe będą najbardziej aktywne i kiedy?
Odpowiedzi na te pytania mogą mieć ogromne znaczenie przy podejmowaniu decyzji o obsadzie personelu w danym dniu, aby zapewnić sprawne funkcjonowanie klubu w godzinach największego ruchu.
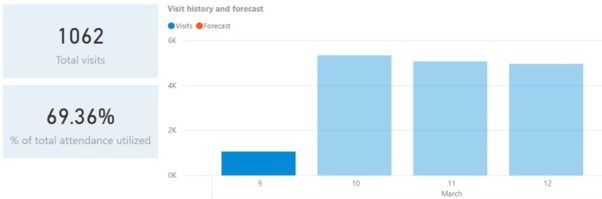
Dzięki uczeniu maszynowemu na siłowni, możesz otrzymywać takie przewidywania tygodnie, a nawet miesiące do przodu, z aktualizacjami dokonywanymi w czasie rzeczywistym.
Na przykład, w miarę jak algorytmy będą się uczyć, będą aktualizować swoje przewidywania dotyczące frekwencji w zależności od zmiennych wejściowych, takich jak:
- Frekwencja klientów w danym czasie
- Przypadkowe wizyty
- Rezerwacje zajęć a rzeczywista frekwencja
- Pogoda
Ostatecznie czynniki te (oraz wiele innych) są ważone w odniesieniu do zapisów historycznych dla każdej zmiennej wejściowej oraz tego, jak każda z nich wpływa na pozostałe.
Dla przykładu, większa liczba regularnych uczestników zwiększa prawdopodobieństwo większej liczby gości, ponieważ często towarzyszą oni stałemu klientowi, który ich zachęcił. Można też obliczyć, że w poprzednie deszczowe dni frekwencja w klubie spadła o 7% i uwzględnić to w nadchodzących prognozach pogody.
Jak widać, możliwości są nieskończone i potrzeba inteligentnego systemu, który będzie w stanie przewidzieć te prognozy z większą dokładnością, aby pomóc Ci określić, jak najlepiej wykorzystać personel i infrastrukturę w celu zwiększenia satysfakcji klientów.
Przewidywania dotyczące sprzedaży
Korzystając z podobnych algorytmów, ale innych zestawów danych niż powyżej, możemy tworzyć prognozy sprzedaży na przyszłość.
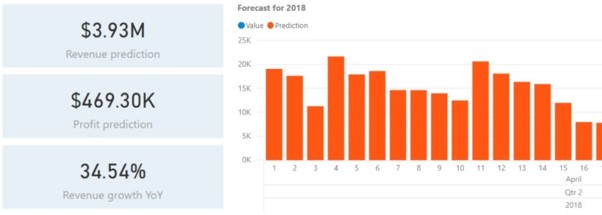
Również w tym przypadku istnieje oczywiście ogromna zależność od właściwego wykorzystania danych historycznych jako zbioru szkoleniowego. Niemniej, po opracowaniu zatwierdzonego modelu można go wykorzystać do przetwarzania bieżących danych sprzedażowych i tworzenia przyszłych prognoz z dużą dokładnością.
Jest to naprawdę przydatne, gdy decydujesz, kiedy powinieneś przeprowadzić kampanie promocyjne w klubie.
Co więcej, można zagłębić się w dane, aby sprawdzić, które grupy demograficzne - pod względem płci i wieku - przyniosą największe przychody, i skierować do nich dodatkowe kupony lub vouchery.
Można to zrobić w odniesieniu do poszczególnych placówek, grup klientów, a nawet całej sieci.
Przewidywanie rezygnacji
Być może jednym z najważniejszych modeli potrzebnych w branży zarządzania siłownią jest model przewidywania rezygnacji.
Jak wspomniano w przykładach powyżej, modele te wykorzystują różne algorytmy uczenia nadzorowanego, aby przypisać prawdopodobieństwo rezygnacji dla poszczególnych klientów oraz - w sposób zagregowany - dla całych klubów.
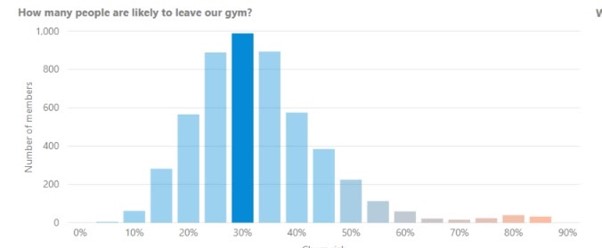
Podobnie jak w przypadku rekomendacji, przewidywania te stają się z czasem coraz dokładniejsze, ponieważ gromadzi się więcej danych, a algorytmy uczą się na podstawie poprawnych i niepoprawnych przewidywań.
Dodatkowo, w miarę jak algorytmy będą się uczyć, będą one zmieniać "wagę" lub wpływ poszczególnych zmiennych wejściowych, jeśli z czasem będą one coraz częściej występować u rezygnujących klientów.
Na przykład, z czasem algorytmy mogą zauważyć, że - odkąd recepcja nie sprzedaje już pewnego rodzaju suplementów - duża liczba klientów, którzy kupowali te suplementy, częściej rezygnuje.
W tej sytuacji dane historyczne związane z zakupem tych suplementów, jako dane wejściowe, miałyby przypisaną większą "wagę" w obliczeniach prawdopodobieństwa rezygnacji.
Zasadniczo wszystko sprowadza się do danych, jakimi dysponuje klub, oraz do tego, jak uczenie maszynowe może je przeanalizować w celu znalezienia korelacji, które w przeciwnym razie pozostałyby niezauważone przez ludzkie oczy.
Wnioski
Analiza danych znalazła już swoje miejsce w wielu, jeśli nie w większości branż na całym świecie. W zarządzaniu klubami fitness, dyscyplina ta zyskuje rozgłos na naszych oczach.
To zastanawiające, że - mimo wszystkich danym gromadzonym przez osoby trzecie - siłownie dopiero teraz zaczynają dostrzegać korzyści płynące z uczenia maszynowego i sztucznej inteligencji, jako realnych rozwiązań w procesie podejmowania decyzji.
To już nie jest marzenie o przyszłości, a rzeczywistość. Tu i teraz.