
Vraag: Heeft uw sportschool een data-analist in dienst?
U weet wel, de man die in een donker verlichte achterkamer tonnen gegevens van sportschoolleden doorspit en af en toe zijn kantoor uitloopt om bicep curls te doen tussen het inzetten van classificatiealgoritmen voor verschillende modellen voor machinaal leren door?
Dat dachten we niet.
Laten we eerlijk zijn: in de afgelopen jaren zijn veel sportscholen overgestapt van het afdrukken van lidmaatschapscontracten van 20 pagina's, het fotokopiëren van rijbewijzen en het vullen van enveloppen met coupons naar het moderniseren van verschillende clubactiviteiten met zelfbedieningskiosken, toegangscontroles en geautomatiseerde correspondentie met leden.
Het is duidelijk dat we een lange weg hebben afgelegd. En wat is het volgende?
Steeds meer bedrijven maken gebruik van voorspellende analyses om hen te helpen bij het nemen van beslissingen en de sportschoolsector staat op het punt hetzelfde te doen.
Maar buiten de grote fitnesscentra heeft vrijwel geen enkele club een interne analist in dienst genomen om voorspellingen te doen of aanbevelingen te doen over verschillende clubprocessen op basis van gegevens van leden.
En aangezien analytics nu in bijna elke branche een prominentere rol speelt, is het tijd voor fitnesscentra om 'slimmer' te worden, om eindelijk de grote hoeveelheden gegevens van leden waarover ze beschikken te gebruiken om beter geïnformeerde beslissingen mee te nemen.
Dit brengt ons bij Machine Learning, het proces van het inzetten van complexe algoritmen om te leren om uitkomsten te voorspellen of af te leiden op basis van data-analyse.
Machine learning wordt al op grote schaal gebruikt in een verscheidenheid van industrieën, zoals, maar niet beperkt tot:
- Online detailhandel
- Zelfrijdende auto's
- Financiële handel
- Zoekmachines
- Entertainment bedrijven
De grote knoop die al deze industrieën samenbindt is, natuurlijk, data... heel veel data.
En het is door het verzamelen en analyseren van deze gegevens via machine learning dat deze industrieën, zoals e-commerce, hun verkoopsinkomsten verhogen met 5-20%..
Maar het is belangrijk op te merken dat binnen sportschoolmanagement, verkoop slechts de helft van de strijd is - er is ook retentie om zorgen over te maken! Uiteindelijk kan machine learning clubs voorzien van:
- Inkomstenvoorspellingen
- Voorspellingen van opzeggingen
- Klasse-aanbevelingen
- Product aanbevelingen
- Motivatiesystemen voor leden
Zodra de gegevens zijn geanalyseerd en de voorspellingen klaar zijn, kunnen de meest relevante acties automatisch worden ondernomen dankzij de kracht van AI.
Maar voordat we er dieper op ingaan, laten we u eerst zien hoe machine learning samenwerkt met clubmanagement.
Verzamelen van gegevens
Net zoals een auto benzine nodig heeft, hebben algoritmes voor machinaal leren gegevens nodig om te analyseren en te verwerken om resultaten te voorspellen en aanbevelingen te doen.
Gelukkig is de fitnessbranche al oververzadigd met geïntegreerde apps en apparaten die fungeren als gegevensbakens om het proces van machinaal leren te voeden. Alles van calorieëntellers tot workout trackers en FitBits, de gegevens zijn er.
Maar zelfs zonder apps van derden beschikt uw club waarschijnlijk al over genoeg gegevens van leden van de eerste partij om slimme aanbevelingen en voorspellingen te doen, gewoon op basis van:
- Aanwezigheidsgeschiedenis
- Leeftijd
- Geslacht
- Aankoopgeschiedenis club
- Boekingen geschiedenis
Dit zijn natuurlijk maar een paar datapunten die kunnen helpen bij het bepalen van specifieke resultaten zoals churn of klasaanbevelingen, maar de mogelijkheden zijn bijna eindeloos, afhankelijk van wat voor soort dataverzameling beacons je hebt geïntegreerd met je systeem.
Het leerproces
Zodra je deze gegevens hebt (met goedkeuring van de klant) kunnen ze worden gebruikt als een trainingsset voor machine learning algoritmen om van te leren.
Machine Learning is in wezen een groot onderdeel van Artificial Intelligence (AI) dat het besluitvormingsproces informeert door correlaties te vinden tussen verschillende datasets.
Met behulp van verschillende algoritmen zal een machine-leermodule in wezen op een "gesuperviseerde" manier leren op een "trainingsset", waarbij elke ingevoerde dataset of "input" wordt gekoppeld aan een verwacht resultaat of "output".
Als we iets willen classificeren als zijnde een appel of geen appel, dan zouden we deze datapunten, gelijk gewogen, als onze verwachte outputs kunnen gebruiken:
- Rood = J/N
- Rond = J/N
- Vrucht = J/N
- Gewicht tussen 70-100 gram J/N
In sommige trainingsreeksen wegen we elke inputvariabele als we ze willen uitdrukken als waarschijnlijkheden. In ons appelvoorbeeld geven we elke invoer hetzelfde gewicht.
Dus, als een object ¾ van deze verwachte inputs bevat, dan heeft het object 75% kans om een appel te zijn in ons model.
Terugkomend op club management, laten we zeggen dat we willen voorspellen welke leden in de nabije toekomst waarschijnlijk zullen veranderen en welke niet.
Als we alle hierboven opgesomde datapunten zouden nemen voor leden van de fitnessclub in het afgelopen jaar, dan zouden we een resultaat labelen als "veranderd" of "niet veranderd" op basis van of de klant veranderd is of niet.
Vervolgens trainen we het algoritme door alle inputs voor elk lid (aanwezigheid, leeftijd, geslacht, enz.) met hun gedefinieerde labels (gewijzigd of niet gewijzigd) in onze trainingsset op te nemen.
Aangezien we onze resultaten willen uitdrukken als waarschijnlijkheden, kunnen we aan elke inputvariabele een "gewicht" toekennen, waarbij sommige meer wegen dan andere
Na verloop van tijd zal het algoritme verschillende variabelen wegen als het leert
Onze trainingsset zou er zo uit kunnen zien, maar dan met veel meer inputs:

Zodra de gegevens zijn "geleerd", verwijderen we de verwachte labels (gekoerst of niet gekoerst) en kijken we of het model de inputgegevens correct kan gebruiken om de uitkomsten te voorspellen op basis van de gegevens waarvan het heeft geleerd.
Nadat de verschillende modellen door de trainingssets zijn gelopen, controleren we hun nauwkeurigheid in de testsets en kiezen we het meest nauwkeurige en stabiele (het verschil in nauwkeurigheid tussen de training- en de testset) model.
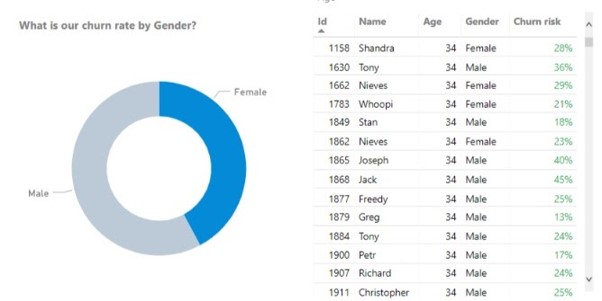
Dit kan ook omgekeerd worden voor andere resultaten zoals productaanbevelingen op productbasis, klasse-aanbevelingen, en meer.
Zodra we onze geclassificeerde groepen hebben (churn-risico vs. niet-churn-risico) is het tijd om actie te ondernemen.
De intelligentie
AI fungeert uiteindelijk als de overkoepelende discipline voor verschillende voorspellende analyses, machinaal leren, taal, visie en andere communicatiesystemen en -processen.
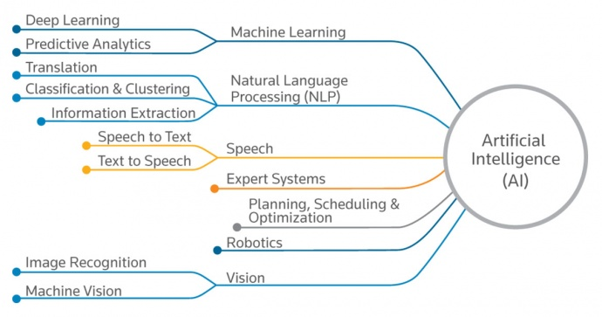
Zodra we een model voor machinaal leren hebben dat we hebben gevalideerd en in productie hebben genomen, zouden we de gegevens gebruiken om een omgeving te creëren waaruit onze AI kan putten.
Wanneer de gegevens door Machine Learning zijn verzameld en klaar zijn om te worden omgezet in actie, zullen AI-automatiseringsprocessen beginnen met het A/B-testen van verschillende communicatiekanalen en berichten om te leren welke het meest effectief zijn.
Machine Learning kan bijvoorbeeld aanbevelen om een specifieke groep clubleden een pakket met persoonlijke trainingen of gereduceerde lidmaatschapsprijzen aan te bieden.
De club zou een paar verschillende berichten voor hetzelfde aanbod hebben gemaakt waaruit de AI kan kiezen. Vervolgens zou de AI elk bericht testen, de resultaten evalueren en de best presterende opties dienovereenkomstig uitrollen voor vergelijkbare toekomstige doelgroepen.
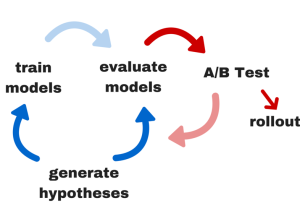
Er zijn natuurlijk nog veel meer bewegende delen achter de schermen; maar dit is een algemene benadering van hoe inhoudselectie plaatsvindt.
Nu we het algemene proces kennen, laten we eens kijken naar enkele specifieke gebruikscases voor clubs.
De slimme sportschool
Door processen van machinaal leren te gebruiken, kunnen clubs nu voorspellingen en aanbevelingen doen over een breed scala aan clubactiviteiten, niet alleen om hun bottom line te verbeteren, maar ook om leden tevreden te houden en op koers te houden om hun doelen te bereiken.
Vergeet niet dat mensen naar sportscholen komen met doelen die geworteld zijn in zelfverbetering. Verbeteringen in de manier waarop u met hen in contact komt, kunnen het verschil maken tussen een onvolledig nieuwjaarsvoornemen en een leven dat voor de lange termijn en ten goede is veranderd.
Product Aanbevelingen
Er is het oude gezegde dat "de klant altijd gelijk heeft".
Dit motto komt voort uit een basisbegrip tussen verkopers- en consumententransacties: je weet niet wat de klant wil totdat hij erom vraagt.
In de huidige tijd hebben fitnessklanten het vaak te druk om de telefoon te pakken en te bellen om hun lidmaatschap te verlengen of om vijf minuten langer aan de balie te wachten om hun drankje voor na de training op te halen.
Daarom zijn productaanbevelingen bijna universeel in elk online retailbedrijf. En ze worden langzaamaan meer en meer gestuurd door machine learning processen om de verkoop te stimuleren.
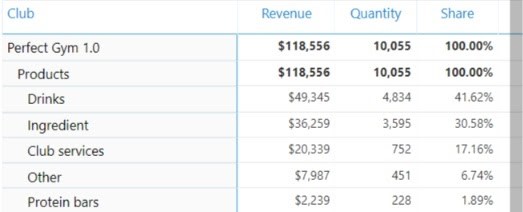
Deze aanbevelingen worden bepaald door verschillende algoritmen voor machinaal leren. Ze kunnen gebaseerd zijn op niet-supervised learning algoritmes die correlaties vinden tussen gekochte items.
De algoritmen kunnen bijvoorbeeld detecteren dat mensen die proteïnepoeder en creatine kopen, vaak ook pre-workoutdrankjes kopen. Deze algoritmen zouden deze correlaties vinden en pre-workoutdrankjes aanbevelen aan mensen die ook vaak de andere twee artikelen kopen.
Aanbevelingen kunnen ook worden gebaseerd op algoritmen voor gesuperviseerd leren, met als voorbeeld dat veel mensen die een gemeenschappelijke outputvariabele deelden (aankoop van een eiwitreep) ook een aantal gemeenschappelijke inputvariabelen hadden (frequente aanwezigheid, vergelijkbare lidmaatschappen, geslacht, gewicht, enz.
Het eindresultaat is een indrukwekkend systeem van associatieregels die worden gebruikt bij het aanbevelen van producten aan klanten, of het nu aan de balie is voor receptionisten om te gebruiken of in uw digitale of promotionele outreach.
Klasse aanbevelingen
Met behulp van soortgelijke technieken die worden gebruikt bij productaanbevelingen, kunnen we aanbevelen welke lessen moeten worden aangeboden om boekingen en bezoekersaantallen te verhogen.
De dataverzameling beacons voor deze zijn een beetje complexer omdat het meer specifieke ledengegevens vereist zoals:
- Frequentie van lesbezoek
- Les boekingsfrequentie
- Klasse beoordelingen
- Lid doelen
- Voorkeuren van leden voor trainingen
Dit zijn slechts een paar punten die kunnen worden gebruikt als inputvariabelen, maar ze kunnen samen met andere gegevens worden gebruikt om bepaalde lessen te vervangen door andere om de betrokkenheid te vergroten.
Dit kan worden bereikt met supervised learning algoritmes, unsupervised, of beide. De eindresultaten zijn aanbevolen klassen met hun voorspelde groei in aanwezigheid.
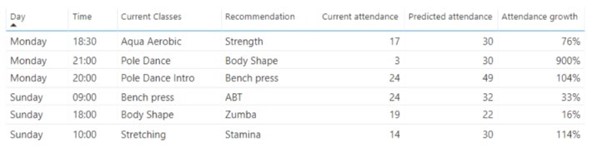
Veel aanbevelingsalgoritmen maken gebruik van een combinatie van gesuperviseerde en niet gesuperviseerde leertechnieken; het belangrijkste aspect is echter dat de algoritmen leren welke aanbevelingen succesvol zijn en deze in de loop van de tijd verbeteren.
Voorspellingen van het aantal leden
Hoeveel leden zullen er op een bepaalde dag in uw club zijn? Hoeveel van hen zullen gloednieuw zijn? Welke leeftijdsgroepen zullen het meest actief zijn en wanneer?
De antwoorden op deze vragen kunnen een enorm verschil maken bij beslissingen over de personeelsbezetting op een bepaalde dag, om ervoor te zorgen dat de club goed draait op piekuren.
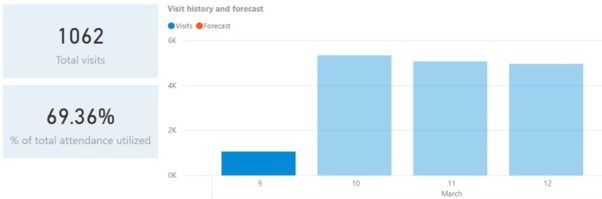
Met machine learning in uw sportschool kunt u deze voorspellingen weken of zelfs maanden van tevoren laten doen, met updates in real time.
Bijvoorbeeld, als de algoritmen blijven leren, zullen ze hun opkomstvoorspellingen bijwerken, afhankelijk van inputvariabelen zoals:
- Lid opkomst in de tijd
- Willekeurige walk-ins
- Boekingen vs. werkelijke aanwezigheid
- Weer
Uiteindelijk worden deze factoren (in combinatie met nog veel meer) gewogen tegen historische records voor elke input variabele en hoe elk van invloed is op de andere.
Bijvoorbeeld, een hoger aantal regelmatige bezoekers verhoogt de waarschijnlijkheid van meer gasten omdat zij vaak het lid vergezellen dat hen heeft doorverwezen. Of het berekent dat de opkomst op regenachtige dagen in het verleden met 7% daalde en houdt daar rekening mee met de komende weerberichten.
Zoals u ziet, zijn de machinaties eindeloos en is er een slim systeem nodig om deze voorspellingen met grotere nauwkeurigheid te doen om u te helpen bepalen hoe u uw personeel en faciliteiten het beste kunt inzetten voor meer tevredenheid.
Voorspellingen van de verkoop
Met soortgelijke algoritmen, maar andere datasets dan hierboven, kunnen wij verkoopvoorspellingen doen voor toekomstige data.
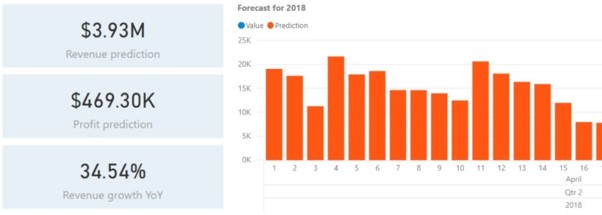
Ook hier is er natuurlijk een groot vertrouwen in het gebruik van historische gegevens als een trainingsset, maar zodra een gevalideerd model is geproduceerd, kan het worden gebruikt om de huidige verkoopgegevens te verwerken en toekomstige voorspellingen te doen met een grotere nauwkeurigheid in de tijd.
Dit komt echt van pas wanneer u moet beslissen wanneer u clubpromotiecampagnes moet opzetten.
Bovendien kunt u in de gegevens inzoomen om te zien welke demografische groepen in termen van geslacht en leeftijd naar verwachting de meeste inkomsten zullen opleveren en de voorspelde minder goed presterende groepen met extra coupons of vouchers benaderen.
Dit kan gebeuren per club, gegroepeerd of zelfs voor een hele keten.
Churn-voorspellingen
Misschien wel een van de belangrijkste modellen die in de hele sportschoolmanagementsector nodig zijn, is het churnvoorspellingsmodel.
Zoals in de voorbeelden hierboven vermeld, wordt hierbij gebruik gemaakt van verschillende algoritmes voor gesuperviseerd leren om opzeggingskansen toe te kennen aan individuele leden en in totaal voor hele clubs.
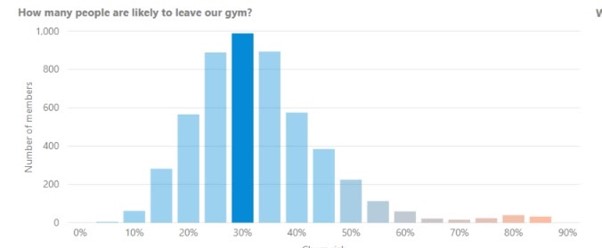
Net als bij aanbevelingen zullen deze voorspellingen na verloop van tijd nauwkeuriger worden naarmate meer gegevens worden verzameld en het model leert van juiste en onjuiste voorspellingen die het doet.
Bovendien zullen de algoritmen, naarmate ze verder leren, het 'gewicht' of de invloed van bepaalde inputvariabelen aanpassen als ze na verloop van tijd vaker voorkomen bij leden die een nieuwe club hebben gekozen.
Na verloop van tijd merken de algoritmen bijvoorbeeld op dat sinds de receptie een bepaald soort supplement niet meer verkoopt, een groot aantal leden die dat supplement kochten, vaker een abonnement opzeggen.
De historische gegevens in verband met de aankoop van deze supplementen, als een input, zou beginnen te worden gewogen in churn waarschijnlijkheid berekeningen.
In wezen komt het allemaal neer op de gegevens waarover uw club beschikt en hoe machine learning deze kan analyseren om correlaties te vinden die anders door mensenogen onopgemerkt zouden blijven.
Conclusie
Data-analyse heeft al een plaats gevonden in veel, zo niet de meeste, bedrijfstakken over de hele wereld. Binnen het management van fitnessclubs is de discipline al voor onze ogen aan het materialiseren.
Het is een groot wonder dat met alle van de 1st partij gegevens die sportscholen accumuleren het is nu net beginnen te kijken in de richting van de voordelen van machine learning en AI als levensvatbare oplossingen voor de besluitvorming.
Het is niet langer een toekomstdroom; het is hier. Nu.